
当ページは工事中です
プロンプトを巡る考察
- プロンプトのマニュアル生成
GPT-3ではユーザーが手作業でプロンプトを記述する必要がある。プロンプト記述は容易ではない。 - プロンプトの自動生成(例 Prompt Tuning)
最適なプロンプトの自動生成する手法として様々な提案が生まれ、代表的なものとしてAUTOPROMPT、Prefix Tuning、 P-Tuning、Prompt Tuning が挙げられる。各タスクにとって最適なプロンプトを「学習」に拠って探索するという点ではすべて共通である。
以下ではPrompt Tuningの概要である。
説明をここに記述 (工事中)
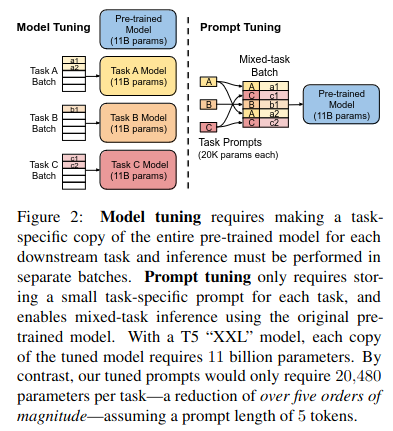
Prompt Tuningのコンセプトを知る上での重要なのは左の内容である。破線の左側は従来のModel Tuning、即ちFine Tuningを行うケースであり、各A,B,Cタスクごとにモデルを作成する。(黄色のモデル、オレンジ色のモデル、赤色のモデル) 破線右側がPrompt Tuningであるが、各A,B,Cタスクごとに必要なものは”Task Prompts(20K params each)”というプロンプト(黄色はタスクA用のTask Prompt、オレンジ色はタスクB用のTask Prompt、赤色はタスクC用のTask Prompt)であり、モデルは水色の共通モデル(事前学習しただけのモデル)である。各タスクに最適なプロンプトを探索する学習プロセスがPrompt Tuningである
説明をここに記述 (工事中)
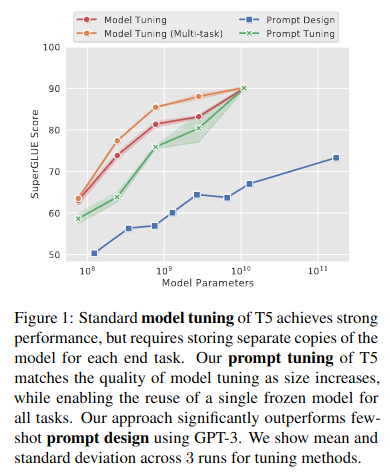
左のFig.1では、Fine Tuningを行ったモデル(赤色、オレンジ色)とGPT-3モデル(青色)の間には性能ギャップがあることを示すと同時に、最適なプロンプトの自動生成を行うPrompt Tuning(緑色)がモデル規模が1010(10 Billion)パラメータ数程度に大規模化するとFine Tuningモデルとほぼ同等のスコア得ることを示している。
Prompt Tuningは手作業に拠るプロンプト記述(Fine Tuning)に勝り、モデルのパラメータ数が10 Billion程度に大規模化するとFine Tuningの場合と同等の性能スコアを得ることができるという点は重要である。
プロンプトの自動生成についての課題: 各タスクごとにPrompt Tuningを事前に行っておく必要があると云う点では、staticなモデルであることに変わりない。
創発能力の出現: モデルのパラメータ数が10 Billionを超えると出現 初見タスクを数個の例で理解できるのはナゼ?
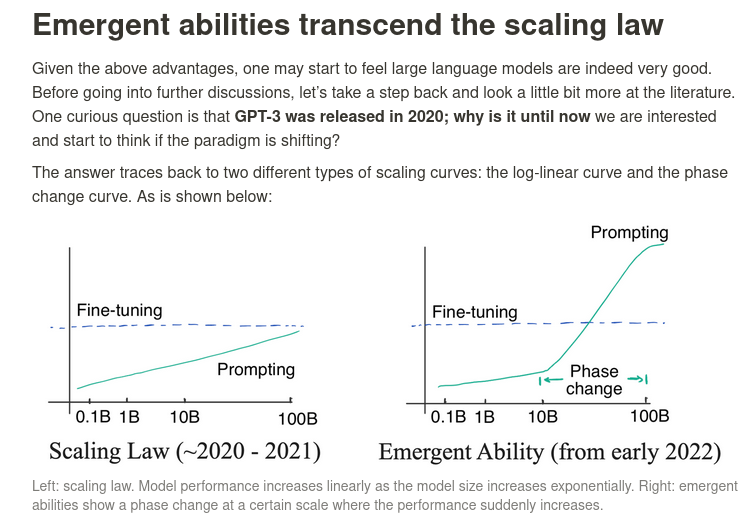
2020年ころまでは、モデルの性能はモデル規模の対数表現に対して線形比例すると考えられてきたが(以下左図)、現在我々が目にしているのはモデルが一定規模以上になるとモデル性能が上昇する勾配が急に変化するという現象である。(以下右図) 一体なぜこのような能力が出現するのだろうか・・
引用: A Closer Look at Large Language Models Emergent Abilities
創発能力の出現 説明(1)
引用: An Explanation of In-context Learning as Implicit Bayesian Inference

創発能力の出現 説明(2)
引用: Transformers learn in-context by gradient descent
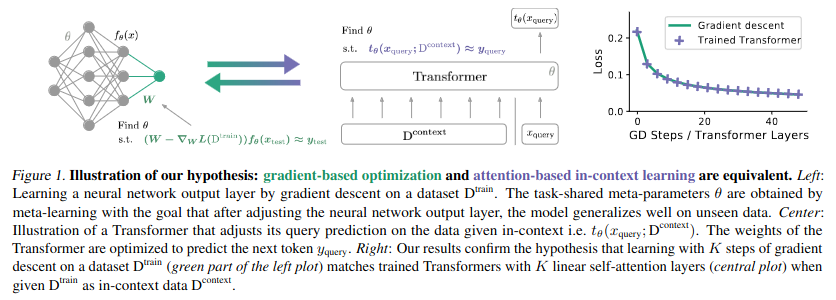
タスクのコンセプトをすぐさまに理解するIn-context Learning能力がどのようにして実現しているのかについては、例えば以下のような考え方も示されている。左のモデルは事前学習したモデルパラメータ(θ)をフリーズし、その上に標準的な勾配降下法でW(Weight)を調整可能なレイヤをのせている。還元すれば、大多数の基盤ネットワークはθをフリーズさせながらも、最上位レイヤについては実行時に動的に更新可能なパラメータとすることでIn-context Learning能力を獲得するコンセプトを表したモデルである。この方法の場合、モデルの挙動を決定するものは、入力データとWeightの2つしか存在しないので、In-context Learning能力を実現するにはWightパラメータの一部(最上位レイヤ)を動的に変更できるしかけが必要となってしまう。
同じことをTransformerで実現できるのではないかというのが中央の図である。この場合も事前学習したモデルパラメータ(θ)をフリーズするが、勾配降下法とは異なり入力データとWeight(=θ)以外にDcontextもTransformerの挙動決定に寄与する。(これはself-attentionが行う) 以下の論文では、Dcontextの存在がIn-context Learning能力の出現に関わっているという考え方を示し、実験的にその証明を試みている。
self-attentionの[keys, values]の値次第で、in-context learningも可能となるとしても、conetxtが途切れる切れ目を理解できなければいけないのではないか・・? ただ、即興学習(動的理解)ともいえるin-context learningが可能であるならば、今後もっと大きなブレイクスルーが出現するのではないか。 「学ぶ方法」を学ぶ能力を獲得すれば、当然成長は加速する。
メタ学習の向かう先
参照: General-Purpose In-Context Learning by Meta-Learning Transformers